

출처: GitHub
중국의 거대 IT기업인 알리바바 그룹의 지능형 컴퓨팅 연구소에서 지난 2월 28일, 새로운 AI 영상 생성 모델인 EMO를 공개했습니다. Emote Portrait Alive 라는 문구와 함께 공개된 이 모델은 말 그대로 살아있는 초상화를 만들 수 있는 생성 모델인데요.
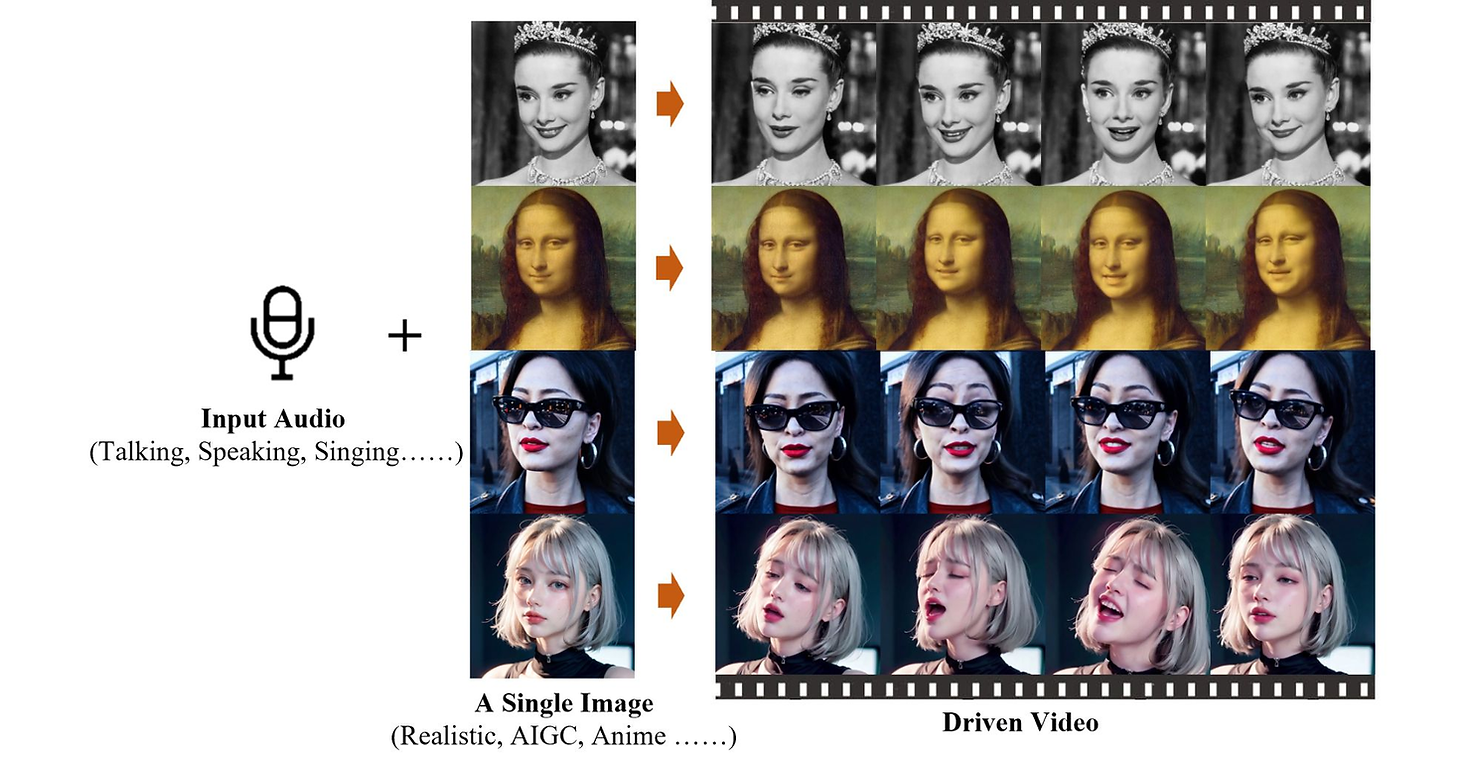
사용자가 인물이나 캐릭터 이미지를 오디오 클립과 함께 입력하면, 이미지 속 인물이나 캐릭터가 오디오의 내용에 맞춰 말하거나 노래를 하는 영상을 생성하는 모델입니다.
해당 프로젝트 페이지에 따르면, 이 모델은 오디오에서 느껴지는 뉘앙스에 맞춰 얼굴 표정을 생성할 수 있으며 어조에 맞는 자연스러운 고개 움직임까지 생성한다고 합니다. 또 중국어, 한국어를 비롯한 다양한
언어를 소화하며 랩이나 힙합같은 빠른 속도의 오디오 클립에도 정확한 입 모양을 생성할 수 있다고 하네요.
EMO의 생성 능력, 같이 한 번 보실까요?
EMO의 기술이 특히 놀라운 이유는 기존에 존재하던 동일한 형식의 Talking Head 모델들에 비해 인물의 표정이나 움직임이 훨씬 풍부하고 자연스러워졌다는 점인데요. 연구진이 발표한 EMO 논문에 그 이유가 잘 나와있습니다.
발간된 논문에 따르면, Talking-head video generation, 즉 음성 신호에 맞는 동영상 생성을 위해 흔히 사용되던 기존의 생성 모델들은 생성 작업을 단순화 하기 위해 생성 결과물에 제한을 거는 경우가 많았다고 합니다. 예를 들어, 얼굴 3D 모델의 facial keypoint 등을 이용하여 제한된 공간에서 얼굴의 변화를 예측하거나, base video의 머리 움직임을 추출하여 생성 영상의 가이드로 적용하는 등의 방식을 이용하였죠. 이러한 방식들은 생성 작업의 복잡도를 낮추긴 하지만, 동시에 최종 결과물의 풍부함과 자연스러움이 저하되는 결과를 가져왔습니다.
반면 EMO는 확산 모델(diffusion model)을 이용해 입력된 오디오 파일의 파형과 인코딩된 레퍼런스 이미지를 분석한 후, 소리의 강도, 높낮이, 강도 등을 파악해 그에 맞는 자연스러운 입술 움직임, 표정, 머리 움직임을 바로 생성할 수 있는 모델입니다.
이렇게 음성 데이터를 통한 직접적인 생성이 가능한 이유는 방대한 데이터셋 학습을 기반으로 한 프레임 엔코딩(FrameEncoding) 과정을 거쳤기 때문인데요.

출처: GitHub
EMO를 학습시키기 위해 연구진은 250시간이 넘는 영상 파일과 1억 5000만장이 넘는 이미지 파일을 수집한 데이터셋을 구축했다고 합니다. EMO는 이 데이터셋을 통해 사람이 말을 하거나 노래를 부를 때 어떤 표정과 움직임을 보이는지 학습한 후, 프레임 엔코딩 과정을 통해 주어진 이미지 속 인물의 모든 표정과 움직임에 대응할 수 있는 능력을 갖추게 되었다고 하네요.
EMO 모델의 놀라운 기술력에 대중들의 반응 또한 엇갈리고 있는데요. 사진 속 인물에게 원하는 말을 하게 하고 노래를 부르게 할 수 있다는 것에 대한 놀라움과 신기함을 표하는 이들이 있는 반면, 악용의 위험을 걱정하는 반응도 심심치 않게 보이는 것 같습니다.
하루가 다르게 발전하고 있는 생성 AI의 기술력, 우리 사회의 새로운 기회일까요, 다가오는 위협일까요?
여러분들의 생각은 어떠신가요?